Улучшаем производительность запросов, меняя IN-подзапросы на производные таблицы
Дата: 31.12.2016
Данный материал является переводом статьи Øystein Grøvlen.
В MySQL 5.6 добавили преобразование IN-подзапросов в semi-join. Появились новые стратегии для выполнения IN-подзапросов; исчезла необходимость выполнять подзапрос для каждой строки внешнего запроса. Это резко повысило производительность многих таких запросов. Однако, преобразование в semi-join применимо не для всех типов запросов. Например, если подзапрос содержит GROUP BY, то его нельзя преобразовать в semi-join. (Полный список ограничений представлен в документации).
К счастью, в MySQL 5.6 также добавили материализацию подзапросов, которая может быть использована для независимых подзапросов, которые нельзя преобразовать в semi-join. (Независимые - это такие подзапросы, которые не содержат ссылок на таблицы внешнего запроса.) В одной из ранее написанных статей, я показал как для запроса №18 из теста DBT-3 изменяется время выполнения с длительности более месяца до нескольких секунд за счет использования стратегии материализации подзапроса. В данной статье я покажу как можно ещё улучшить производительность этого запроса, переписав его.
В исходном варианте запрос №18 выглядит следующим образом:
SELECT c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, SUM(l_quantity)
FROM customer, orders, lineitem
WHERE o_orderkey IN (
SELECT l_orderkey
FROM lineitem
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 313
)
AND c_custkey = o_custkey
AND o_orderkey = l_orderkey
GROUP BY c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice
ORDER BY o_totalprice DESC, o_orderdate
LIMIT 100;
Этот запрос называется Large Volume Customer Query, т.к. он находит крупные заказы (более 313 товаров) и возвращает первые 100 заказов после сортировки по итоговой цене и дате. В MySQL 5.5 и ранее подзапрос выполнялся для каждой строки внешнего запроса. В MySQL 5.6 стратегия материализации сделала возможным однократное выполнение подзапроса. Это можно увидеть в плане выполнения, который показывает EXPLAIN для этого запроса (часть колонок опущена для удобства восприятия):
id select_type table type key rows Extra
1 PRIMARY orders ALL NULL 1500000 Using where; Using temporary; Using filesort
1 PRIMARY customer eq_ref PRIMARY 1 NULL
1 PRIMARY lineitem ref i_l_orderkey_quantity 4 Using index
2 SUBQUERY lineitem index i_l_orderkey_quantity 6001215 Using index
Тип выборки SUBQUERY означает, что запрос выполняется однократно. (В противном случае тип выборки был бы DEPENDENT SUBQUERY.) Вот диаграмма, которую показывает Visual EXPLAIN для этого случая:
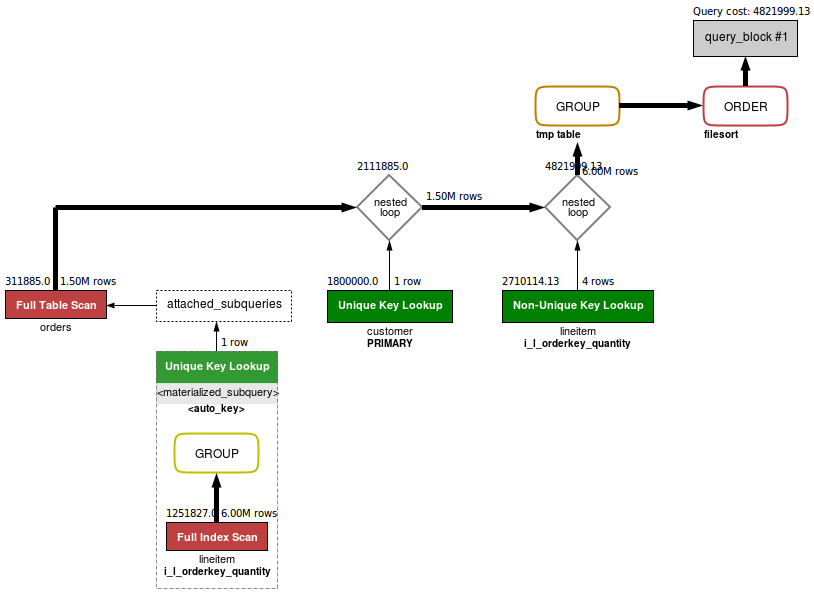
Основной компонент обеих стратегий (и преобразования в semi-join, и материализации) - это исключение дубликатов. В отличии от операции JOIN, результат которой содержит все комбинации строк, соответствующих условию соединения, выражения с предикатом IN возвращают только по одной строке независимо от количества совпадений в подзапросе. При трансформации в semi-join существует несколько способов исключение дубликатов, при материализации только один - с помощью временной таблицы.
Внимательно посмотрев на запрос № 18, мы можем понять, что подзапрос никогда не вернет дубликатов. Выбирается только одно поле `l_orderkey` и по этому полю проводится группировка, т.е. все строки, возвращаемые подзапросом, будут уникальными. Это означает, что мы можем заменить IN-выражение на join и получить эквивалентный запрос:
SELECT c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, SUM(lineitem.l_quantity)
FROM customer, orders, lineitem,
( SELECT l_orderkey
FROM lineitem
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 313
) l2
WHERE o_orderkey = l2.l_orderkey
AND c_custkey = o_custkey
AND o_orderkey = lineitem.l_orderkey
GROUP BY c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice
ORDER BY o_totalprice DESC, o_orderdate
LIMIT 100;
Теперь наш подзапрос стал производной таблицей (так называется подзапрос в части FROM). План выполнения для переписанного запроса выглядит следующим образом:
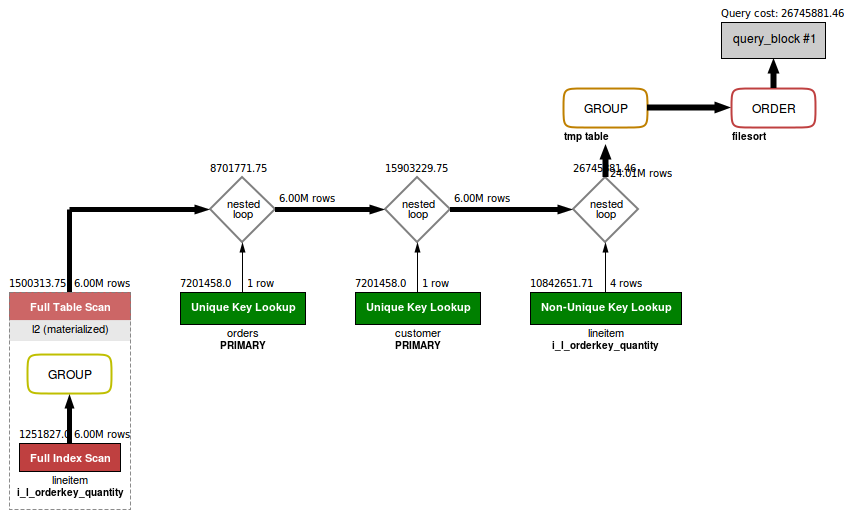
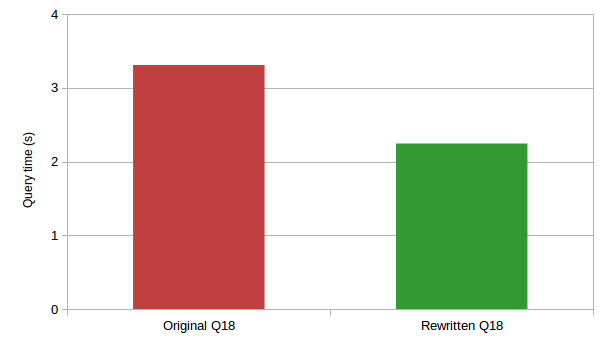
Обратите внимание, подзапрос материализуется как и раньше, но теперь происходит полное сканирование временной таблицы, а не таблицы orders как было в исходном запросе. Это означает, что вместо перебора всех заказов MySQL перебирает только большие заказы (более 313 товаров). Учитывая, что большинство заказов содержит меньше товаров, такое преобразование должно дать улучшение производительности. Действительно, в MySQL 5.7.14 время выполнения переписанного запроса сократилось где-то на треть:
Замена IN-подзапросов на производные таблицы дает возможность оптимизатору выбрать оптимальный порядок соединения таблиц. Эта же идея лежит в основе semi-join преобразования, которое, начиная с MySQL 5.6, производится автоматически, и именно поэтому наше ручное преобразование улучшило план выполнения. Надеюсь, когда-нибудь в будущем оптимизатор MySQL научится делать такие преобразования автоматически. А пока, следите за возможностью вручную переписать IN-подзапросы в тех случаях, когда к ним не применимо преобразование в semi-join!
Дата публикации: 31.12.2016
© Все права на данную статью принадлежат порталу SQLInfo.ru. Перепечатка в интернет-изданиях разрешается только с указанием автора и прямой ссылки на оригинальную статью. Перепечатка в бумажных изданиях допускается только с разрешения редакции.
|