Задавайте вопросы, мы ответим
Вы не зашли.

Всем привет.
На рабочем проекте столкнулся с непонятной ситуацией - апдейты счётчиков (`counter`=`counter`+1) периодически (не понятно по какой периодичности) не могут долго получить лок, из-за чего сам апдейт может выполняться от нескольких секунд вплоть до минуты. Проблема может не возникать (либо мы не успеваем её заметить) многие дни, но вот за последнюю неделю уже 4й случай, из них два случая рано утром, когда активность в проекте минимальна. Т.к. апдейты сыпятся в несколько потоков, замечено, что при их уменьшении апдейты отрабатывают быстрее, но потоков максимум 30, что не может давать какую-либо серьёзную нагрузку.
Параллельных запросов в эти моменты можно сказать, что нет. Иногда видно, что апдейты сыпятся в одну и ту же запись, тогда вроде бы логично, но, во-первых, 30 апдейтов одной и той же записи не могут выполняться 40-50 секунд, а во-вторых, апдейты чаще всего выполняются синхронно, т.е. они все висят Х секунд и потом все моментально отрабатывают.
В INFORMATION_SCHEMA.INNODB_LOCK_WAITS при 30 потоках 300-400 записей, при 10 потоках 40-50.
Вот некоторые переменные состояния: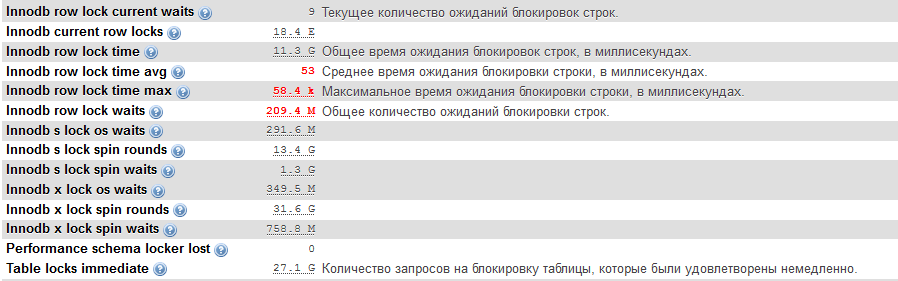
Innodb row lock current waits обычно соответствует количеству апдейтов, ожидающих лок.
В состоянии ОСи и железе никаких проблем не выявлено. Есть мысли какие провести оптимизации, чтобы уменьшить количество апдейтов, но это лечение симптомов болезни, а хотелось бы понять её причины. Подскажите кто-нибудь, куда копать?
Отредактированно Neval (24.09.2018 11:35:42)
Неактивен

По Вашей статистике только 1% запросов ожидает блокировку и занимает это в среднем 53 мс. Это может быть нормальным, если используется жесткий диск и все транзакции немедленно сбрасываются на диск (innodb_flush_log_at_trx_commit=1). Попробуйте установить этот параметр в 0, если проект в случае сбоя допускает потерю транзакций за секунду. Места на диске достаточно?
Неактивен
Если оно висит по минуте, то это можно отследить снаружи каким-нибудь приложением, которое смотрит за SHOW ENGINE INNODB STATUS. Нужно посмотреть на блокировки. Скорее всего, дело не в движке таки, а в транзакциях, которые друг друга блокируют (и посмотрите на deadlocks, кстати, возможно, там будет сразу видно, чего ждет транзакция).
Неактивен
rgbeast, это пишущая нода кластера на Перконе, так-что блокировки за 800 дней аптайма там бывали всякие разные. Сейчас innodb_flush_log_at_trx_commit=0, диск ентерпрайз ссд с физическим первым рейдом, места свободного не много, но есть гигов 30 точно + свободный тейблспейс гигов на 100 (после чистки), в соседней ветке я жаловался на него ![]() Проблема не постоянна, это и не даёт возможности понять её причины.
Проблема не постоянна, это и не даёт возможности понять её причины.
paulus, я пока-что глазами мониторю процессы и переменные состояния, у SHOW ENGINE INNODB STATUS выдача большая, но я не понимаю на что стоит обращать внимание. Дедлоков кстати мало, за последние два дня их стало +2, а глюк был вчера и сегодня.
Сейчас вот ситуация дошла до критичной и мне пришлось вообще отключить апдейты счётчиков, чтобы обработать накопившуюся очередь задач. 50 потоков обработчика задач по началу обрабатывали по несколько сотен задач в секунду (1 задача = 1 проблемный апдейт, который был отключен), но после обработки 300 тысяч задач проблема опять стала проявляться, но уже на других апдейтах - обновление баланса пользователя. Получается, что переполняется какой-то буфер локов, но я не знаю как его зовут и где его искать.
Но если сейчас всё логично, что из-за апдейта 300к записей новые апдейты ждут своего лока, то в случае с апдейтом счётчиков не логично, ведь проблема дважды проявлялась с утра, когда активность минимальна.
Неактивен
Если это не standalone сервер, то может быть разное. Смотрите на flow control в первую очередь, это основная проблема торможений галеры:
https://www.percona.com/blog/2013/05/02 … for-mysql/
На всякий случай — вы же пишете в одну ноду?
Неактивен
Да, вся запись в одной ноде. flow control ведь влияет на реплику, в моём случае до неё даже очередь не доходит, сначала ведь запись лочится/апдейтится, а уже потом разливается по кластеру.
Для эксперимента мы переключали запись на другую ноду кластера в момент наличия проблемы, там ситуация была аналогичная, при чём сразу же. Т.е. я так понимаю, что буфер локов общий на весь кластер?
Неактивен
Всё, разобрался, спасибо за помощь. Найдя в INNODB STATUS фразу "lock_mode X locks rec but not gap waiting" и почитав информацию по "gap locks" понял, что моё представление о работе транзакций не соответствует действительности. В коде буквально с месяц назад описанные выше апдейты были завёрнуты в транзакцию, сейчас отключил транзакцию и теперь всё пулей.
Неактивен