Задавайте вопросы, мы ответим
Вы не зашли.
Добрый день.
Уже довольно долго бьюсь над одним запросом, но пока желаемого результата не достиг. Есть сомнение в правильном ли я вообще двигаюсь направлении, поэтому решил обратиться к сообществу.
Есть таблица с полями: 'sessionId', 'userId', 'time'.
Задача состоит в следующем. Необходимо выбрать для каждого уникального 'userId', все записи содержащие в себе один из двух наиболее ранних уникальных 'sessionId'.
Замудрено наверное получилось попробую показать на примере:
Исходные данные: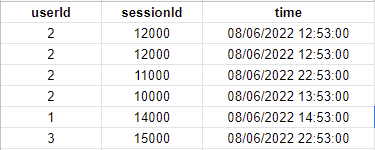
Результат:
В итоге мы избавились от записи "2|11000|08/06/2022 22:53:00" т.к. данный sessioId наиболее поздний и уже не влазит в лимит для данного userId.
Идея решения состоит в том чтобы в начале сделать выборку из уникальных userId, а уже по ним подбирать наши сессии.
Неактивен

см https://sqlinfo.ru/articles/info/45.html
это позволит вам выбрать по 2 наиболее ранних sessionId для каждого userId
потом ещё 1 join чтобы выбрать все соответствующие имя записи
Неактивен
vasya написал:
см https://sqlinfo.ru/articles/info/45.html
это позволит вам выбрать по 2 наиболее ранних sessionId для каждого userId
Неактивен
Вообще-то ваш пример возвращает набор
10000
11000
14000
15000
т.е. по 2 последних sessionId для каждого userId. Просто для userId в исходных данных всего по 1 строке. См http://sqlfiddle.com/#!9/d06880/1
Но это, конечно, счастливая случайность, т.к. в статье
Предполагается, что комбинация (user_id, date_added) уникальна, т.е. пользователь не может разместить 2 сообщения в один момент времени.
Т.е. просто в лоб переписать запросы не выйдет, их нужно будет дорабатывать.
Что касается ошибки, см
Обратите внимание: в режиме ONLY_FULL_GROUP_BY придется усложнять запрос: сначала выбрать нужные post_id, затем по ним дополнительным join извлечь остальные поля (подробнее см статью Группировка в MySQL)...
Неактивен